
| Version 53 (modified by lvpeng, 14 years ago) (diff) |
|---|
FGBI
Traditional Xen-based systems track memory updates by keeping evidence of the dirty pages at each migration epoch. In Remus (and in our previous work LLM), the same page size as that of Xen (for x86, this is 4KB) is used as the granularity for detecting memory changes. However, when running computationally intensive workloads under LLM, the downtime becomes unacceptably long. FGBI (Fine-Grained Block Identification) is a mechanism, which uses smaller memory blocks (smaller than a page size) as the granularity for detecting memory changes. FGBI calculates the hash value for each memory block at the beginning of each migration epoch. At the end of each epoch, instead of transferring the whole dirty page, FGBI computes new hash values for each block and compares them with the corresponding old values. Blocks are only modified if their corresponding hash values don’t match. Therefore, FGBI marks such blocks as dirty and replaces the old hash values with the new ones. Afterwards, FGBI only transfers dirty blocks to the backup host.
FGBI is based on The Remus project and the Lightweight Live Migration (LLM) mechanism. For a full description and evaluation, please see our OPODIS'11 paper.
The Downtime Problem in LLM

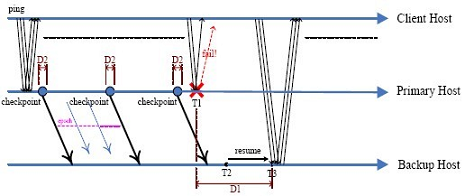
Figure 1. Primary-Backup model and the downtime problem.
Downtime is the primary factor for estimating the high availability of a system, since any long downtime experience for clients may result in loss of client loyalty and thus revenue loss. Under the Primary-Backup model (Figure 1), there are two types of downtime: I) the time from when the primary host crashes until the VM resumes from the last checkpointed state on the backup host and starts to handle client requests (D1 = T3 - T1); and II) the time from when the VM pauses on the primary (to save for the checkpoint) until it resumes (D2). From the SSS'10 paper, we observe that for memory-intensive workloads running on guest VMs (such as the highSys workload), LLM endures much longer type I downtime than Remus. This is because, such workloads update the guest memory at high frequency. In contrast, LLM migrates the guest VM image update (mostly from memory) at low frequency, but uses input replay as an auxiliary. Thus, when a failure happens, a significant number of memory updates are needed in order to ensure synchronization between the primary and backup hosts. Therefore, LLM needs significantly more time for the input replay process in order to resume the VM on the backup host and begin handling client requests.
There are several migration epochs between two checkpoints, and the newly updated memory data is copied to the backup host at each epoch. At the last epoch, the VM running on the primary host is suspended and the remaining memory states are transferred to the backup host. Thus, the type II downtime depends on the amount of memory that remains to be copied and transferred when pausing the VM on the primary host. If we reduce the dirty data which need to be transferred at the last epoch, then we can reduce the type II downtime. Moreover, if we synchronize the memory state between the primary and backup hosts all the time, and reduce the transferred data at each epoch, then at the last epoch, there won’t be significant memory updates that need to be transferred. Thus, we can also reduce type I downtime.
FGBI Design
Therefore, in order to reduce the downtime under memory-intensive workloads and increase availability, we propose a memory synchronization technique for tracking memory updates, called Fine-Grained Block Identification (or FGBI). As pointed out before, Remus and LLM track memory updates by keeping evidence of the dirty pages at each migration epoch. Remus uses the same page size as Xen (for x86, this is 4KB), which is also the granularity for detecting memory changes. However, this mechanism is not efficient. For instance, no matter what changes an application makes to a memory page, even just modify a boolean variable, the whole page will still be marked dirty. Thus, instead of one byte, the whole page needs to be transferred at the end of each epoch. Therefore, it is logical to consider tracking the memory update at a finer granularity, like dividing the memory into smaller blocks.
The FGBI mechanism uses memory blocks (smaller than page sizes) as the granularity for detecting memory changes. FBGI calculates the hash value for each memory block at the beginning of each migration epoch. Then it uses the same mechanism as Remus to detect dirty pages. However, at the end of each epoch, instead of transferring the whole dirty page, FGBI computes new hash values for each block and compares them with the corresponding old values. Blocks are only modified if their corresponding hash values do not match. Therefore, FGBI marks such blocks as dirty and replaces the old hash values with the new ones. Afterwards, FGBI only transfers dirty blocks to the backup host.
However, because of using block granularity, FGBI introduces new overhead. If we want to accurately approximate the true dirty region, we need to set the block size as small as possible. For example, to obtain the highest accuracy, the best block size is one bit. But that is impractical, because it requires storing an additional bit for each bit in memory, which means that we need to double the main memory. Thus, a smaller block size leads to a greater number of blocks and also requires more memory for storing the hash values. We present two techniques to reduce the memory overhead: block sharing and hybrid compression.
Downtime Evaluations
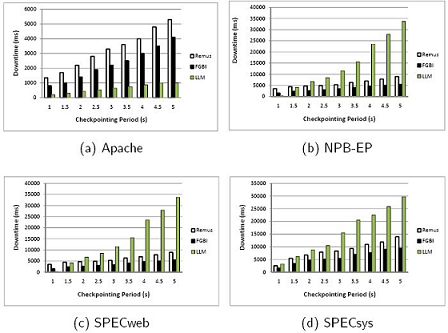
Figure 2. Type I Downtime comparison under di fferent benchmarks: (a)Apache. (b)NPB-EP. (c)SPECweb. (d)SPECsys.
Figures 2(a), 2(b), 2(c), and 2(d) show the type I downtime comparison among FGBI, LLM, and Remus mechanisms under Apache, NPB-EP, SPECweb, and SPECsys applications, respectively. The block size used in all experiments is 64 bytes. For Remus and FGBI, the checkpointing period is the time interval of system update migration, whereas for LLM, the checkpointing period represents the interval of network buffer migration. By configuring the same value for the checkpointing frequency of Remus/FGBI and the network buffer frequency of LLM, we ensure the fairness of the comparison. We observe that Figures 2(a) and 2(b) show a reverse relationship between FGBI and LLM. Under Apache (Figure 2(a)), the network load is high but system updates are rare. Therefore, LLM performs better than FGBI, since it uses a much higher frequency to migrate the network service requests. On the other hand, when running memory-intensive applications (Figure 2(b) and 2(d)), which involve high computational loads, LLM endures a much longer downtime than FGBI (even worse than Remus).
Although SPECweb is a web workload, it still has a high page modification rate, which is approximately 12,000 pages/second. In our experiment, the 1 Gbps migration link is capable of transferring approximately 25,000 pages/second. Thus, SPECweb is not a lightweight computational workload for these migration mechanisms. As a result, the relationship between FGBI and LLM in Figure 2(c) is more similar to that in Figure 2(b) (and also Figure 2(d)), rather than Figure 2(a). In conclusion, compared with LLM, FGBI reduces the downtime by as much as 77%. Moreover, compared with Remus, FGBI yields a shorter downtime, by as much as 31% under Apache, 45% under NPB-EP, 39% under SPECweb, and 35% under SPECsys.
Table 1. Type II Downtime comparison.
Table 1 shows the type II downtime comparison among Remus, LLM, and FGBI mechanisms under different applications. We have three main observations. First, the downtime results are very similar for the idle run case. This is because, Remus is a fast checkpointing mechanism and both LLM and FGBI are based on it. Memory update are rare during idle runs, so the type II downtime in all three mechanisms is short and similar. Second, when running the NPB-EP application, the guest VM memory is updated at high frequency. When saving the checkpoint, LLM takes much more time to save large "dirty" data caused by its low memory transfer frequency. Therefore in this case, FGBI achieves a much lower downtime than Remus (reduction is more than 70%) and LLM (reduction is more than 90%). Finally, when running the Apache application, the memory update is not so much as that when running NPB, but the memory update is significantly more than the idle run. The downtime results show that FGBI still outperforms both Remus and LLM.
Overhead
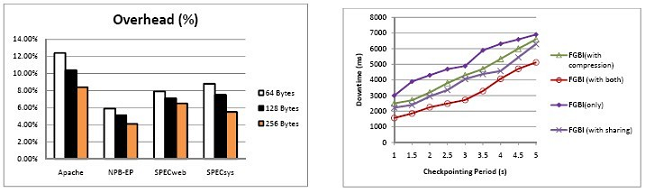
Figure 3. (a) Overhead under di fferent block size. (b) comparison of proposed techniques.
Figure 3(a) shows the overhead during VM migration. The figure compares the applications' runtime with and without migration, under Apache, SPECweb, NPB-EP, and SPECsys, with the size of the fine-grained blocks varying from 64 bytes to 128 bytes and 256 bytes. We observe that, in all cases, the overhead is low, no more than 13% (Apache with 64 byte block). As discussed before, the smaller the block size that FGBI chooses, the greater is the memory overhead that it introduces. In our experiments, the smaller block size that we chose is 64 bytes, so this is the worst case overhead compared with the other block sizes. Even in this "worst" case, under all the benchmarks, the overhead is less than 8.21%, on average.
In order to understand the respective contributions of the three proposed techniques (i.e., FGBI, sharing, and compression), Figure 3(b) shows the break- down of the performance improvement among them under the NPB-EP benchmark. The figure compares the downtime between integrated FGBI (which we use for evaluation here), FGBI with sharing but no compression support, FGBI with compression but no sharing support, and FGBI without sharing nor compression support, under the NPB-EP benchmark. As previously discussed, since NPB-EP is a memory-intensive workload, it should present a clear difference among the three techniques, all of which focus on reducing the memory- related overhead. We do not include the downtime of LLM here, since for this compute-intensive benchmark, LLM incurs a very long downtime, which is more than 10 times the downtime that FGBI incurs.
We observe from Figure 3(b) that if we just apply the FGBI mechanism without integrating sharing or compression support, the downtime is reduced, compared with that of Remus in Figure 3(b), but it is not significant (reduction is no more than twenty percent). However, compared with FGBI with no support, after integrating hybrid compression, FGBI further reduces the downtime, by as much as 22%. We also obtain a similar benefit after adding the sharing support (down- time reduction is a further 26%). If we integrate both sharing and compression support, the downtime is reduced by as much as 33%, compared to FGBI without sharing or compression support.
Attachments (4)
- figure1.png (72.0 KB) - added by lvpeng 14 years ago.
- figure2.png (91.0 KB) - added by lvpeng 14 years ago.
- figure3.png (84.1 KB) - added by lvpeng 14 years ago.
- table1.png (25.8 KB) - added by lvpeng 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip