
| Version 9 (modified by lvpeng, 14 years ago) (diff) |
|---|
FGBI
Traditional xen-based systems track memory updates by keeping evidence of the dirty pages at each migration epoch. For example, Remus uses the same page size as Xen (for x86, this is 4KB), which is also the granularity for detecting memory changes. FGBI (Fine-Grained Block Identification) is a mechanism which uses smaller memory blocks (smaller than page sizes) as the granularity for detecting memory changes. FGBI calculates the hash value for each memory block at the beginning of each migration epoch. At the end of each epoch, instead of transferring the whole dirty page, FGBI computes new hash values for each block and compares them with the corresponding old values. Blocks are only modified if their corresponding hash values don’t match. Therefore, FGBI marks such blocks as dirty and replaces the old hash values with the new ones. Afterwards, FGBI only transfers dirty blocks to the backup host.
FGBI is based on The Remus project and our previous efforts Lightweight Live Migration (LLM) mechanism.
Downtime Problem
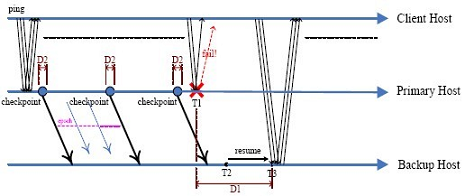
Downtime is the primary factor for estimating the high availability of a system, since any long downtime experience for clients may result in loss of client loyalty and thus revenue loss. Under the Primary-Backup model (Figure 1), there are two types of downtime: I) the time from when the primary host crashes until the VM resumes from the last checkpointed state on the backup host and starts to handle client requests (D1 = T3 - T1); II) the time from when the VM pauses on the primary (to save for the checkpoint) until it resumes (D2). From Jiang’s paper we observe that for memory-intensive workloads running on guest VMs (such as the HighSys? workload), LLM endures much longer type I downtime than Remus. This is because, these workloads update the guest memory at high frequency. On the other side, LLM migrates the guest VM image update (mostly from memory) at low frequency but uses input replay as an auxiliary. In this case, when failure happens, a significant number of memory updates are needed in order to ensure synchronization between the primary and backup hosts. Therefore, it needs significantly more time for the input replay process in order to resume the VM on the backup host and begin handling client requests.
Regarding the type II downtime, there are several migration epochs between two checkpoints, and the newly updated memory data is copied to the backup host at each epoch. At the last epoch, the VM running on the primary host is suspended and the remaining memory states are transferred to the backup host. Thus, the type II downtime depends on the amount of memory that remains to be copied and transferred when pausing the VM on the primary host. If we reduce the dirty data which need to be transferred at the last epoch, then we can reduce the type II downtime. Moreover, if we reduce the dirty data which needs to be transferred at each epoch, trying to synchronize the memory state between primary and backup host all the time, then at the last epoch, there won’t be too much new memory update that need to be transferred, so we can reduce the type I downtime too.
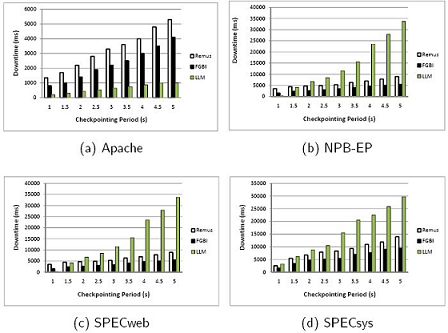
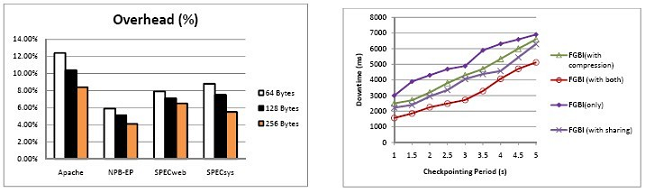
Therefore, in order to achieve HA in these virtualized systems, especially to address the downtime problem under memory-intensive workloads, we propose a memory synchronization technique for tracking memory updates, called Fine-Grained Block Identification (or FGBI). Our main contributions includes: FGBI tracks and transfers the memory updates efficiently, by reducing the total number of dirty bytes which need to be transferred from primary to backup host. Besides, we integrate memory block sharing support with FGBI to reduce the newly-introduced memory overheads. In addition, we also support a hybrid compression mechanism among the memory dirty blocks to further reduce the migration traffic in the transfer period. Our experimental results reveal that FGBI reduces the type I downtime over LLM and Remus by as much as 77% and 45% respectively, and reduces the type II downtime by more than 90% and 70% compared with LLM and Remus, respectively.
FGBI Design
Remus and LLM track memory updates by keeping evidence of the dirty pages at each migration epoch. Remus uses the same page size as Xen (for x86, this is 4KB), which is also the granularity for detecting memory changes. However, this mechanism is not efficient. For instance, no matter what changes an application makes to a memory page, even just modify a boolean variable, the whole page will still be marked dirty. Thus, instead of one byte, the whole page needs to be transferred at the end of each epoch. Therefore, it is logical to consider tracking the memory update at a finer granularity, like dividing the memory into smaller blocks.
We propose the FGBI mechanism which uses memory blocks (smaller than page sizes) as the granularity for detecting memory changes. FBGI calculates the hash value for each memory block at the beginning of each migration epoch. Then it uses the same mechanism as Remus to detect dirty pages. However, at the end of each epoch, instead of transferring the whole dirty page, FGBI computes new hash values for each block and compares them with the corresponding old values. Blocks are only modified if their corresponding hash values do not match. Therefore, FGBI marks such blocks as dirty and replaces the old hash values with the new ones. Afterwards, FGBI only transfers dirty blocks to the backup host. However, because of using block granularity, FGBI introduces new overhead. If we want to accurately approximate the true dirty region, we need to set the block size as small as possible. For example, to obtain the highest accuracy, the best block size is one bit. That is impractical because it requires storing an additional bit for each bit in memory, which means that we need to double the main memory. Thus, a smaller block size leads to a greater number of blocks and also requires more memory for storing the hash values. Based on these past e orts illustrating the memory saving potential, we present two supporting techniques: block sharing and hybrid compression.
Attachments (4)
- figure1.png (72.0 KB) - added by lvpeng 14 years ago.
- figure2.png (91.0 KB) - added by lvpeng 14 years ago.
- figure3.png (84.1 KB) - added by lvpeng 14 years ago.
- table1.png (25.8 KB) - added by lvpeng 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip