
| Version 11 (modified by lvpeng, 14 years ago) (diff) |
|---|
LLM
Remus is a periodical live migration process for disaster recovery at configured frequency. However, checkpointing at high frequency will introduce significant overhead, as plenty of resources such as CPU and memory are consumed by the migration. In this case clients that request services may experience significantly long delays. If on the contrary the migration runs at low frequency trying to reduce the overhead, there maybe many service requests that are duplicately served. Actually this will produce the same effect of increasing the downtime from the perspective of those new requests that come after the duplicately served requests. To solve this problem, based on the checkpointing approach of Remus, we developed an integrated live migration mechanism, called Lightweight Live Migration (LLM), which consists of both whole-system checkpointing and input replay. For a full description and evaluation, please see our SSS'10 paper.
LLM's Architecture

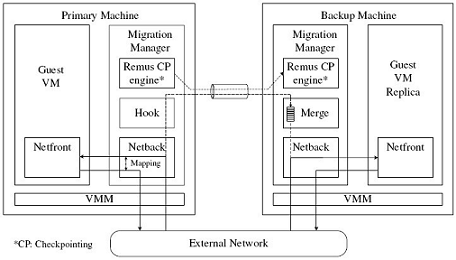
We design the implementation architecture of LLM as shown in Figure 1. Beyond Remus, we also migrate the change in network driver buffers. The entire process works as follows:
1) First, on the primary machine, we setup the mapping between the ingress buffer and the egress buffer, signifying which packets are generated corresponding to which service request(s), and which requests are yet to be served. Moreover, LLM hooks a copy for each ingress service request.
2) Second, at each migration pause, LLM migrates the hooked copy as well as the boundary information to the backup machine asynchronously, using the same migration socket as the one used by Remus for CPU/memory status updates and writes to the file system.
3) Third, all the migrated service requests are buffered in a queue in the “merge” module. Those buffered requests that have been served will be removed based on the migrated boundary information. Once a failure occurs on the primary machine that breaks the migration data stream, the backup machine recovers the migrated memory image and merges the service requests into the corresponding driver buffers.
Asynchronous Network Buffer Migration In LLM
Checkpointing was used to migrate the ever-changing updates of CPU/memory/disk to the backup machine by Remus. Only at the beginning of each checkpointing cycle, the migration occurs in a burst mode after the guest virtual machine resumes. Most of the time, there is no traffic flowing through the network connection between the primary machine and the backup machine. During this interval, we can migrate the service requests at higher frequency than that of checkpointing.
Like the migration of CPU/memory/disk updates, the migration of service requests is also in an asynchronous manner, i.e., the primary machine can resume its service without waiting for the acknowledgement from the backup machine.
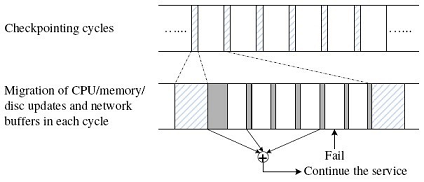
Figure 2 shows the time sequence of migrating the checkpointed resources and the incoming service requests at different frequencies on a single network socket. The entire sequence within an epoch is described as follows:
1) The dashed blocks represent the suspension period when the guest virtual machine is paused. During this suspension period, all the status updates of CPU/memory/disk are collected and stored in a migration buffer.
2) Once the guest VM is resumed, the content stored in the migration buffer is migrated first (shown as a block shaded area that is adjacent to the dashed area in the figure).
3) Then, the network buffer migration starts at high frequency until the guest VM is suspended again. At the end of each network buffer migration cycle (the thin, shaded strips in the figure), LLM transmits two boundary sequence numbers for the moment: one is for the first service request in the current checkpointing period, and the other is for the first service request that has a “False” completion flag. All the services after the first boundary need to be replayed on the backup machine for consistency, but only those after the second boundary need to be responded to the clients. If there is no new requests, LLM transmits the boundary sequence numbers only.
Benchmarks and Measurements
We utilized three network application examples to evaluate the downtime, network delay and overhead of LLM and Remus:
1) Example 1 (highnet)—The first example is flood ping with the interval of 0:01 second, and there is no significant computation task running on domain U. In this case, the network load will be extremely high, but the system updates are not significant. We named it “highnet” to signify the intensity of network load.
2) Example 2 (highsys)—In the second example, we designed a simple application to taint 200 pages (4 KB per page on our platform) per second, and there are no service requests from external clients. Therefore, this example involves a lot of computation workload on domain U. The name “highsys” reflects its intensity on system updates.
3) Example 3 (Kernel Compilation)—We used kernel compilation as the third example which involves all the components in a system, including CPU/memory/disk updates. As part of Xen, we used Linux kernel 2:6:18 directly. Given the limited resource on domain U, we cut the configuration to a small subset in order to reduce the time required to run each experiment.
Evaluation Results
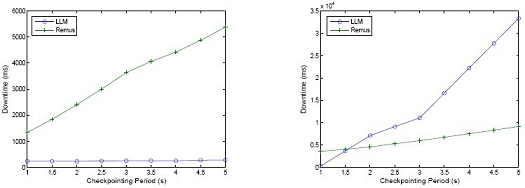
We observe that under highsys, LLM demonstrates a downtime that is longer than, yet comparable to, that of Remus. The reason is that LLM runs at low frequency, hence the migration traffic in each period will be higher than that of Remus. Under highnet, the downtime of LLM and Remus show a reverse relationship where LLM outperforms Remus. This is because, from the client side, there are too many duplicated packets to be served again by the backup machine in Remus. In LLM, on the contrary, the primary machine migrates the request packets as well as boundaries to the backup machine, i.e., only those packets yet to be served will be served by the backup. Thus the client does not need to re-transmit the requests, therefore will experience a much shorter downtime.
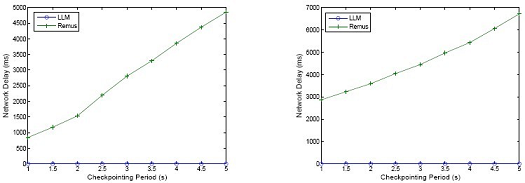
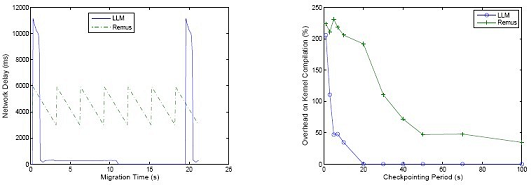
We evaluated the network delay under highnet and highsys as shown in Figures 4. In both cases, we observe that LLM significantly reduces the network delay by removing the egress queue management and releasing responses immediately. In Figure 4, we only recorded the average network delay in a migration period. Next, we show the details of the network delay in a specific migration period in Figure 4, in which the interval between two adjacent peak values represents one migration period.We observe that the network delay of Remus decreases linearly within a period but remains at a plateau. In LLM, on the contrary, the network delay is very high at the beginning of a period, then quickly decrease to nearly zero after a system update is over. Therefore, most of the time, LLM demonstrates a much shorter network delay than Remus.
Figure 5 shows the overhead under kernel compilation. Actually, the overhead significantly changes only in the checkpointing period interval of [1;60] seconds, as shown in the figure. For checkpointing with shorter periods, the migration of system updates may last longer than a configured checkpointing period, therefore the kernel compilation time for these cases are almost the same with minor fluctuation. For checkpointing with longer periods, especially when it is longer than the baseline (i.e., kernel compilation without any checkpointing), a VM suspension may or may not occur during one compilation process. Therefore, the kernel compilation time will be very close to the baseline, meaning a zero percent overhead. Right in this interval, LLM’s overhead due to the suspension of domain U is significantly lower than that of Remus, as it runs at much lower frequency than Remus.
Attachments (5)
- figure1.png (41.0 KB) - added by lvpeng 14 years ago.
- figure2.png (42.5 KB) - added by lvpeng 14 years ago.
- figure3.png (53.7 KB) - added by lvpeng 14 years ago.
- figure4.png (52.6 KB) - added by lvpeng 14 years ago.
- figure5.png (58.6 KB) - added by lvpeng 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip