
| Version 60 (modified by lvpeng, 14 years ago) (diff) |
|---|
VDEchp
A virtual machine (VM) running solo can be stopped and resumed easily, and has much less running cost than physical machines. All of the successful VMs (e.g., Xen, VMware, KVM) have similarly good resume-ability. Our previous work (LLM, FGBI) focuses on achieving high availability by using solo VM. In virtual distributed environments (VDEs), which consist of multiple VMs running on different physical hosts interconnected by a virtual network, the failure of one VM can affect other related VMs and may cause them to also fail. In VDEchp, we develop a lightweight, globally consistent checkpoint mechanism, which checkpoints the entire VDE for immediate restoration after VM failures.
Checkpointing a VDE
A straightforward way of checkpointing a VDE is to restart all VMs in the VDE upon a failure. However, this can lead to significant data loss. Before the failure happens, none of the correct state is saved, neither for each VM nor for the entire VDE. Thus, if the entire VDE were to crash (due to the failure of one VM) just before the completion of a long-running task, all the VMs must be re-started immediately after the failure, resulting in loss of computational time and data. For example, assume that we have two virtual machines, named VM1 and VM2, running in a virtual network. Say, VM2 sends some messages to VM1 and then fails. These messages may be correctly received by VM1 and may change the state of VM1. Thus, when VM2 is rolled-back to its latest correct state, VM1 must also be rolled-back to a state before the messages were received from VM2. In other words, the VMs (and thus the entire VDE) must check-pointed at globally consistent states.
Lightweight Checkpoint Implementation
We deploy the VDEchp agent that encapsulates our checkpointing mechanism on every host. The mechanism uses the same host memory with other running VMs. For each VM on a host, in addition to the memory space assigned to its guest OS, we assign a small amount of additional memory for its VDEchp agent to use. During system initialization, we save the initial state of each VM on the disk. To differentiate this state from the phrase “checkpoint,” we call this state, “stable copy.” After the VMs start execution, the VDEchp agents begin saving the correct state for the VMs. For each VM, during each checkpoint interval, all memory pages are set as read-only. Thus, if there is any write to a page, it will trigger a page fault. Since we leverage the shadow-paging feature of Xen, we are able to control whether a page is read-only and to trace whether a page is dirty. When there is a write to a read-only page, a page fault is triggered and reported to the VMM, and we save the current state of this page.
When a page fault occurs, this memory page is set as writeable, but we don’t save the modified page at this time, because there may be another “new” write to the same page in the same interval. Instead, at the end of each checkpoint interval, we copy the “final” state of the modified page to the agent’s memory, and reset all pages to read-only again. Therefore, each checkpoint consists of only the pages which are updated within that checkpoint interval. And, since each checkpoint interval is very small, the number of updated pages in this interval is small as well, so it is unnecessary to assign large memory to each VDEchp agent.
Different Execution Cases Under VDEchp

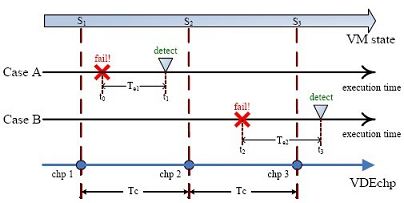
Figure 1. Execution cases under VDEchp.
In the VDEchp design, for each VM, the state of its stable copy is always one checkpoint interval behind the current VM’s state except the initial state. This means that, when a new checkpoint is generated, it is not copied to the stable copy immediately. Instead, the last checkpoint is copied to the stable copy. The reason is that, there is a latency between when an error occurs and when the failure caused by this error is detected.
For example, in Figure 1, an error happens at time t0 and causes the system to fail at time t1. Since most error latency is small, in most cases, t1 - t0 < Te. In the Case A, the latest checkpoint is chp1, and the system needs to roll back to the state S1 by resuming from the checkpoint chp1. However, in the Case B, an error happens at time t2, and then a new checkpoint chp3 is saved. After the system moves to the state S3, this error causes the system to fail at time t3. Here, we assume that t3 - t2 < Te. But, if we choose chp3 as the latest correct checkpoint and roll the system back to state S3, after resuming, the system will fail again. We can see that, in this case, the latest checkpoint should be chp2, and when the system crashes, we should roll it back to state S2, by resuming from the checkpoint chp2.
Definition of Global Checkpoint

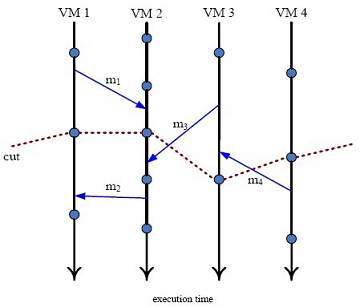
Figure 2. The definition of the global checkpoint.
To compose a globally consistent state of all the VMs, the checkpoint of each VM must be coordinated. Besides checkpointing each VM’s correct state, it’s also essential to guarantee the consistency of all communication states within the virtual network. In Figure 2, the messages exchanged among the VMs are marked by arrows going from the sender to the receiver. The execution line of the VMs is separated by their corresponding checkpoints. The upper part of each checkpoint corresponds to the state before the checkpoint and the lower part of each checkpoint corresponds to the state after the checkpoint. A global checkpoint (consistent or not) is marked as the “cut” line, which separates each VM’s timeline into two parts. We label the messages exchanged in the virtual network into three categories:
- Type (1) message: The state of the message’s source and the destination are on the same side of the cut line. For example, in Figure 2, both the source state and the destination state of message m1 are above the cut line. Similarly, both the source state and the destination state of message m2 are under the cut line.
- Type (2) message: The message’s source state is above the cut line while the destination state is under the cut line, like message m3.
- Type (3) message: The message’s source state is under the cut line while the destination state is above the cut line, like message m4.
For these three types of messages, we can see that a globally consistent cut must ensure the delivery of type (1) and type (2) messages, but avoid type (3) messages. For example, consider the message m4. In VM3’s checkpoint saved on the cut line, m4 is already recorded as being received. However, in VM4’s checkpoint saved on the same cut line, it has no record that m4 has been sent out. Therefore, the state saved on VM4’s global cut is inconsistent, because in VM4’s view, VM3 receives a message m4, which is sent by no one.
Distributed Checkpoint Algorithm in VDEchp
We develop a variant of the simplified version of Mattern’s algorithm used in VNsnap, as the basis of our lightweight checkpoint mechanism. As illustrated before, type (3) messages are unwanted, because they are not recorded in any source VM’s checkpoints, but they are already recorded in some checkpoint of a destination VM. In the VDEchp design, there is always a correct state for the VM, recorded as the stable copy in the disk. The state of stable copy is one checkpoint interval behind the current VM’s state, because we copy the last checkpoint to the stable copy only when we get a new checkpoint. Therefore, before a checkpoint is committed by copying to the stable copy, we buffer all the outgoing messages in the VM during the corresponding checkpoint interval. Thus, type (3) messages are never generated, because the buffered messages are unblocked only after saving their information by copying the checkpoint to the in-disk stable copy. Our algorithm works under the assumption that the buffered messages will not be lost or duplicated.
In the VDEchp design, there are multiple VMs running on different hosts connected within the network. One host is the backup host where we deploy the VDEchp Initiator, and others are primary hosts where we run the protected VMs. The Initiator can be running on a VM which is dedicated to the checkpointing service. It doesn’t need to be deployed on the privileged guest system like the Domain 0 in Xen. When VDEchp starts to record the globally consistent checkpoint, the Initiator broadcasts the checkpoint request and waits for acknowledgements from all the recipients. Upon receiving a checkpoint request, each VM checks the latest recorded in-disk stable copy (not the in-memory checkpoint), marks this stable copy as part of the global checkpoint, and sends a “success” acknowledgement back to the Initiator. The algorithm terminates when the Initiator receives the acknowledgements from all the VMs. For example, if the Initiator sends a request (marked as rn) to checkpoint the entire VDE, a VM named VM1 in the VDE will record a stable copy named “vm1_global_rn”. All of the stable copies from each VM compose a globally consistent checkpoint for the entire VDE. Besides, if the VDEchp Initiator sends the checkpoint request at a user-specified frequency, the correct state of the entire VDE is recorded periodically.
Evaluation Results
Downtime Evaluation for Solo VM

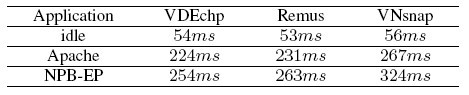
Table 1. Solo VM downtime comparison.
Table I shows the downtime results under different mechanisms. We compare VDEchp with Remus and the VNsnap-memory daemon, under the same checkpoint interval. We measure the downtime of all three mechanisms, with the same VM (with 512MB of RAM), for three cases: a) when the VM is idle, b) when the VM runs the NPB-EP benchmark program, and c) when the VM runs the Apache web server workload.
Several observations are in order regarding the downtime measurements.
First, the downtime results of all three mechanisms are short and very similar for the idle case. This is not surprising, as memory updates are rare during idle runs, so the downtime of all mechanisms is short and similar.
Second, the downtime of both VDEchp and Remus remain almost the same when running NPB-EP and Apache. This is because, the downtime depends on the amount of memory remaining to be copied when the guest VM is suspended. Since both VDEchp and Remus use a high-frequency methodology, the dirty pages in the last round are almost the same.
Third, when running the NPB-EP program, VDEchp has lesser downtime than the Remus and the VNsnap-memory daemon (reduction is more than 20%). This is because, NPB-EP is a computationally intensive workload. Thus, the guest VM memory is updated at high frequency. When saving the checkpoint, compared with other high-frequency checkpoint solutions, the Remus and the VNsnap-memory daemon takes more time to save larger dirty data due to its low memory transfer frequency.
Finally, when running the Apache application, the memory update is not so much as that when running NPB. But the memory update is more than the idle run. The results show that VDEchp has lower downtime than Remus and the VNsnap-memory daemon (downtime is reduced by roughly 16%).
VDE Downtime

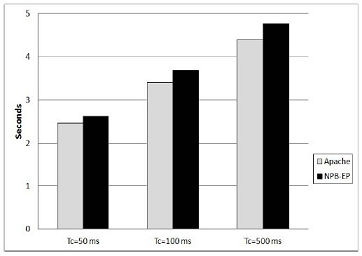
Figure 3. VDE downtime under Apache and NPB benchmarks.
The VDE downtime is the time from when the failure was detected in the VDE until the entire VDE resumes from the last globally consistent checkpoint. We conducted experiments to measure the downtime. To induce failures in the VDE, we developed an application program that causes a segmentation failure after executing for a while. This program is launched on several VMs to generate a failure while the distributed application workload is running in the VDE. The protected VDE is then rolled back to the last globally consistent checkpoint. We use the NPB-EP program (MPI task in the VDE) and the Apache web server benchmark as the distributed workload on the protected VMs.
Figure 3 shows the results. From the figure, we observe that, in our 36-node (VM) environment, the measured VDE downtime under VDEchp ranges from 2.46 seconds to 4.77 seconds, with an average of 3.54 seconds. Another observation is that the VDE downtime in VDEchp slightly increases as the checkpoint interval grows. This is because, the VDE downtime depends on the number of memory pages restored during recovery. Thus, as the checkpoint interval grows, the checkpoint size also grows, so does the number of restored pages during recovery.
For a full description and additional evaluation results, please see our VDEchp Technical Report.
Attachments (4)
- figure2.png (54.6 KB) - added by lvpeng 14 years ago.
- figure1.png (58.6 KB) - added by lvpeng 14 years ago.
- table1.png (21.1 KB) - added by lvpeng 14 years ago.
- figure3.png (23.4 KB) - added by lvpeng 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip